Inhaltsverzeichnis
“Behebe das oder deine Rankings werden schlechter!”
Google macht jetzt Ernst…und Druck. Heute flatterten gleich mehrere Mails von der Google Search Console rein. Der Googlebot kann demnach nicht auf CSS- und JS-Dateien einer Website zugreifen. Weiter unten im Artikel habe ich einen kleinen “Erste-Hilfe-Kurs” für das Beheben dieser Meldung zusammengeschrieben.
“Die Google-Systeme haben kürzlich ein Problem mit Ihrer Startseite festgestellt, das sich auf das Rendern und Indexieren Ihrer Inhalte durch unsere Algorithmen auswirkt. Der Googlebot kann aufgrund von Beschränkungen in Ihrer robots.txt-Datei nicht auf Ihre JavaScript- und/oder CSS-Dateien zugreifen. Anhand dieser Dateien kann Google feststellen, ob Ihre Website ordnungsgemäß funktioniert. Wenn Sie den Zugriff auf diese Dateien blockieren, kann dies zu schlechteren Rankings führen.”

Der rauhe Unterton schwingt mit und Google lässt hier in den Formulierungen eigentlich alles offen, was man eigentlich eingrenzen könnte. “Wenn Sie den Zugriff auf diese Dateien blockieren, kann dies zu schlechteren Rankings führen.” – Hier hat Google vergessen zu erwähnen, dass dies wohl hauptsächlich für die mobile Version zutrifft.
Wie man im Webmaster Central Help Forum lesen kann, gibt es aufgrund dieser Mail ziemlich viel Verwirrung und Unverständnis. So haben doch etliche Webmaster eigentlich immer darauf geachtet, dass Ihre Inhalte gut indexierbar sind.
Warum macht Google so eine Ansage?
Ganz einfach: Automatisierung. Google entwickelt sich als moderne Suchmaschine ständig weiter. Und mit ihr auch die Möglichkeiten.
Das Verlangen, dem Googlebot jetzt CSS- und Javascript Dateien für die Indexierung freizugeben ist eigentlich nur logisch. Google will möglicherweise direkt beim Crawling eine Website rendern um mögliche Darstellungsfehler zu identifizieren, die im reinen Quellcode nicht ersichtlich sind. Fehlerhaftes CSS kann eine Website im Browser auch “total zerschießen” obwohl die Inhalte theoretisch lesbar sind. Ich denke das wird der Grund für diese Mails von Google sein: Das Crawling kommt auf ein neues Level.
Wie ernst sollte ich diese Mails nehmen?
Ehrlich gesagt besteht da jetzt kein Grund zur Panik. Google versucht zwar mit der forschen Formulierung “die Rankings sind in Gefahr” eine Eskalationsstufe auszurufen, allerdings bezweifle ich die zeitnahe Umsetzung aller betroffener Webmaster weltweit. Noch dazu ist diese Mail ja nur ein Hinweis darauf, dass bestimmte Ressourcen der Website (eben CSS und JS-Dateien) nicht crawlbar / renderbar sind bzw. das der Zugriff zu bestimmten Verzeichnissen für Crawler beschränkt wurde, beispielsweise durch die robots.txt.
Die Mail bedeutet aber noch lange nicht, dass 1. Eure Website Darstellungsfehler hat, 2. das es Probleme mit der responsiven (mobilen) Darstellung gibt und 3. das es irgendeine Konsequenz geben wird. Es ist lediglich eine Mitteilung darüber, dass der Googlebot CSS- oder Javascript-Dateien nicht auslesen kann / darf. Thats it!
Denkt man an das Google-Mobile-Friendly-Update und liest man den Inhalt der Hinweis-Mail genauer, so wird schnell klar, dass Google mit den gewünschten Ressourcen scheinbar vorrangig die mobile Version einer Website überprüfen und crawlen möchte bzw. ob eine scheinbar “mobil freundliche” Website auch wirklich so freundlich ist. Denkbar, dass Google den Algorithmus zu Erkennung von für mobile Endgeräte optimierte Webseiten überarbeitet hat.
“Der Googlebot kann nicht auf CSS- und JS-Dateien zugreifen” – Was mach ich denn jetzt nur?
Keine Panik. In den meisten Fällen dürfte sich das Problem durch das Bearbeiten der “robots.txt” erledigt haben. Viele WordPress-User z.B. dürften standardmäßig einen der folgenden Einträge in der robots.txt stehen haben.
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /wp-includes/
Alle diese Verzeichnisse beinhalten CSS- oder Javascript Dateien von PlugIns, Templates oder sonstigen Komponenten. Mit der Anweisung “disallow” wird dem Googlebot der Zugang zu diesen Verzeichnissen verweigert. Man entferne einfach diese Einträge und das Problem sollte sich in den meisten Fällen erledigt haben. In diesem Fall gilt das allerdings nur für WordPress-Seiten. Bei Joomla, Magento, Typo3 und Co. sollte es aber ähnliche Verzeichnisse geben. Einfach mal nachschauen.
Das ist der “rough way”.
Nachtrag 29.07.
Man kann das Ganze auch noch genauer spezifizieren wenn man weiß, wo in welchen Verzeichnissen sich geblockte Ressourcen befinden, z.B. so:
User-agent: *
Disallow: /cgi-bin/
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/cache/
Allow: /wp-content/themes/
Allow: /wp-content/plugins/
Allow: /wp-content/uploads/
Allow: /wp-includes/css/
Allow: /wp-includes/js/
Allow: /wp-includes/images/
Oder man gibt einfach nur dem Googlebot CSS- und Javascript-Dateien frei:
#Googlebot
User-agent: Googlebot
Allow: *.css
Allow: *.js
# Alle anderen User-agent:
* Disallow: /wp-admin/
Disallow: /wp-includes/
Allgemeines zur Robots.txt und das Testen der Änderungen
 Wie eben erwähnt, gibt es verschiedenen Möglichkeiten, dem Googlebot die blockierten Ressourcen freizugeben. Mir erschien es das Einfachste, das direkt über die Dateiendungen zu machen.
Wie eben erwähnt, gibt es verschiedenen Möglichkeiten, dem Googlebot die blockierten Ressourcen freizugeben. Mir erschien es das Einfachste, das direkt über die Dateiendungen zu machen.
Allow: *.css
Allow: *.js
Nun war ich mir aber nicht ganz sicher und habe einfach mal John Mueller von Google gefragt (links auf das Bild klicken zum vergrößern). Der gab auch noch einmal den wichtigen Hinweis, nach den Änderungen in der robots.txt auf jeden Fall den robots.txt-Tester in der Search Console zu benutzen und zu prüfen, ob der Googlebot nun tatsächlich auf die zuvor blockierten Ressourcen zugreifen kann.
Hinweise, wie sich unterschiedliche Anweisungen in der robots.txt beeinflussen können gibt es hier. An dieser Stelle nochmals danke an John für die schnelle Antwort!
Wie nutze ich den robots.txt-Tester? Wie prüfe ich, ob die Änderungen wirksam sind?
Dazu habe ich kurzerhand ein Video aufgenommen.
Ich habe die robots.txt geändert. Was nun?
Nun müsst Ihr noch einen Recrawl bei den Google Webmaster Tools…äh Entschuldigung….bei der Google Search Console anstoßen und ihr solltet danach sehen, ob das Problem weiterhin besteht.
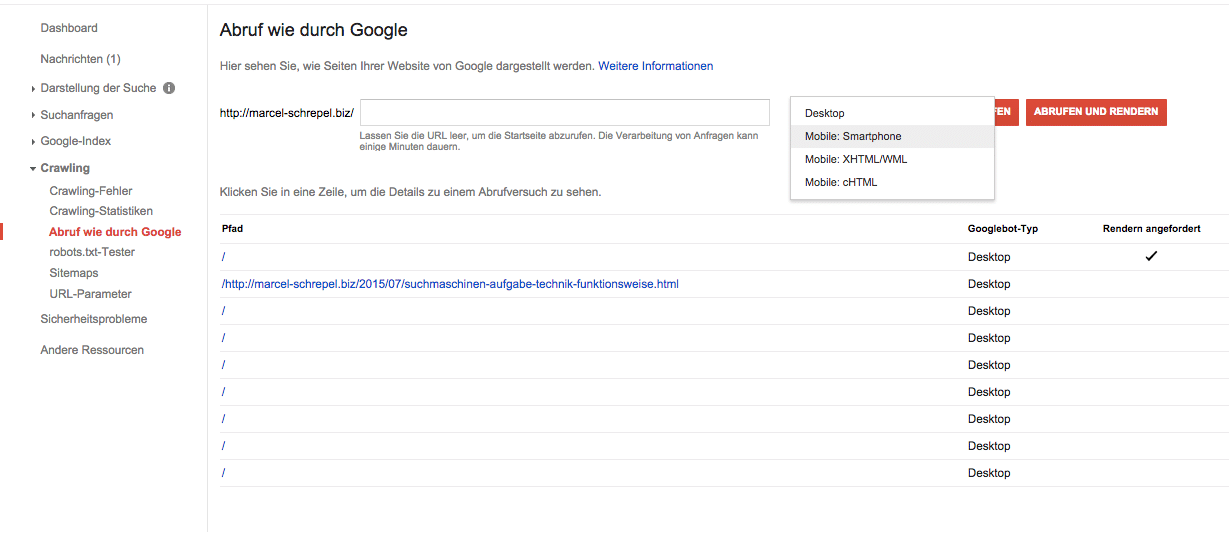
Laut Google kann es eine Weile dauern bis die Änderungen an der robots.txt wahrgenommen und verarbeitet werden.Wie im Video oben könnt Ihr auch einfach den robots.txt-tester zum Testen nehmen.
Google meckert immernoch rum. Was kann ich noch tun?
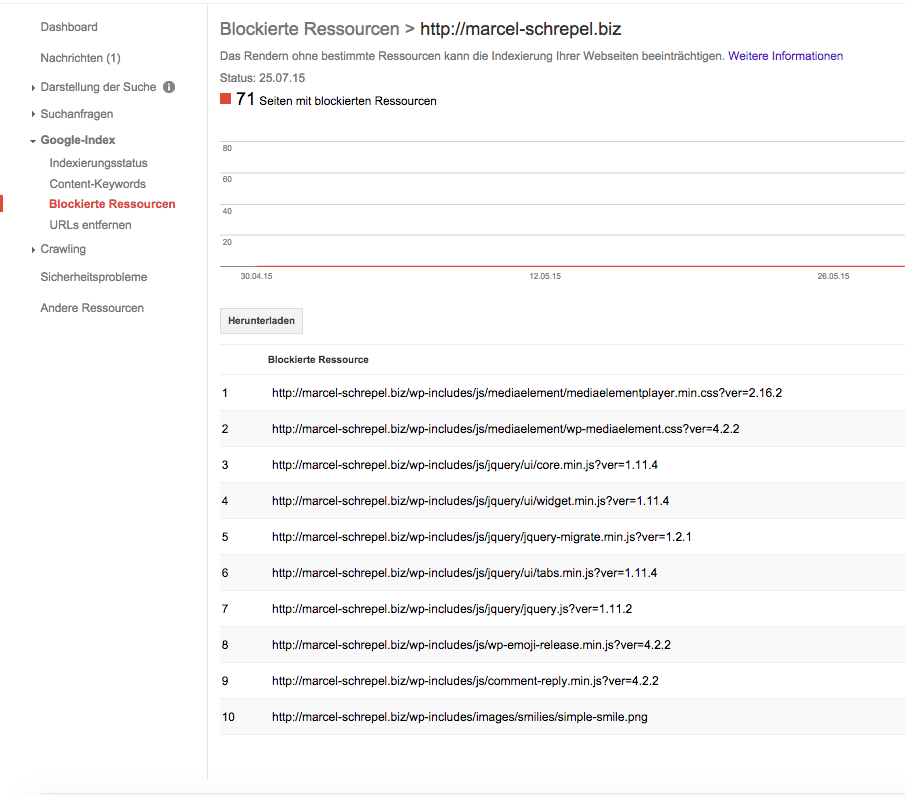
In der Google Search Console kann man direkt sehen, welche Ressourcen nicht crawlbar sind (siehe Screenshot). In meinem Fall sind es alles Dateien im /wp-includes/ Ordner. Schaut einfach in der Search Console nach und ihr werdet sehen, welches Verzeichnis betroffen ist.
Ich habe das alles geprüft. Ich habe immer noch Fehler. Was kann das sein?
Nochmal: Es ist nur eine allgemeine Meldung, dass der Googlebot auf bestimmte Ressourcen nicht zugreifen kann. Einige davon, oder besser die Freigabe dafür, kann man gar nicht steuern (siehe Screenshoot). In meinem Fall sind das Bilder, die in einem eingebetteten Soundcloud- oder Mixcloud Player angezeigt werden. Das kann man getrost ignorieren!
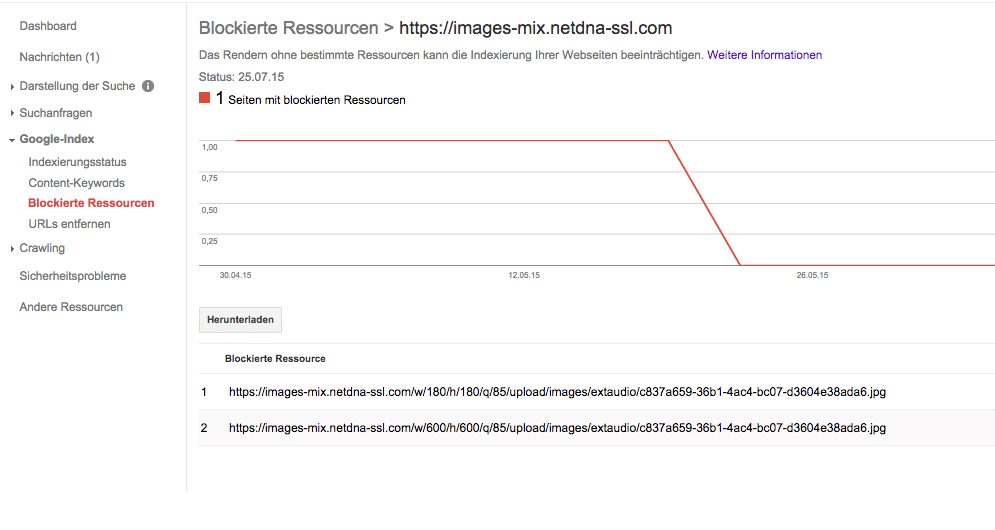
Ebenso wenn man Javascript nur als Make-Up benutzt.
Ole Albers hat dazu gerade auf Google+ einen schönen knackigen Hinweis geliefert:
In erster Linie geht es darum, dass Google mittlerweile eben sehr gut mit JavaScript umgehen kann und lediglich versucht, das gleiche Ergebnis zu bekommen, wie der Anwender.
Wenn Beispielsweise AngularJS verwendet wird und die JavaScript-Dateien blockiert werden, sieht der Anwender anstatt “Buchtitel: Tolle Sache, Seiten: 120” stattdessen: “Buchtitel {Book.Title}, Seiten: {Book.Pages}”
Und das ist natürlich relativ blöd. Wer JS nur zum “Hübschmachen” und nicht für Content verwendet, (und das ist bei WordPress-Installationen ja meist der Fall) kann die Warnung eigentlich ignorieren.
Nachtrag 29.07.- “Abruf wie durch Google” nutzen
Das habe ich oben vergessen zu erwähnen: Man kann über die “Abruf wie durch Google” – Funktion auch direkt überprüfen, ob der Googlebot etwas anderes sieht als ein Nutzer.
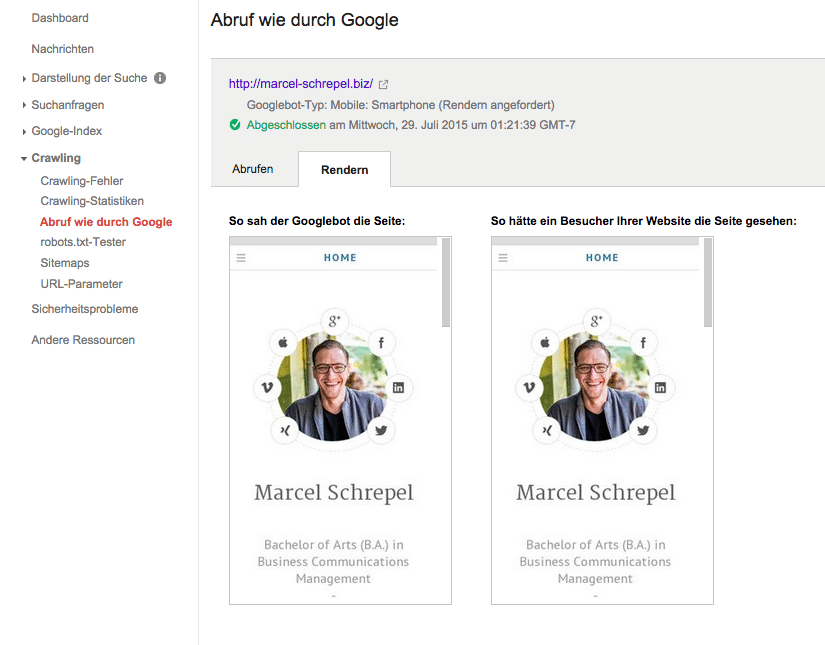
Dazu müsst ihr unbedingt die Option “Rendern” auswählen (Desktop oder Smartphone). Kurz warten und wenn der Status “abgeschlossen” ist einfach auf die Zeile unten klicken. (Google hat das nicht gerade offensichtlich gelöst). Ihr seht nun ganz genau, ob der Googlebot Eure Seite evt. anders sieht.
Google will den /wp-admin/ ordner crawlen. Was nun?
Ich hatte gestern den Fall, dass ein Theme die admin-ajax.php anspricht, welche die CSS rendert. In diesem Fall kann man, sofern es unbedingt sein muss, dem Googlebot nur diese Datei “freigeben”. Der Eintrag in der robots.txt sollte dann so aussehen (Das gilt nur für WordPress!)
User-agent: Googlebot
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php





